Scaling Accelerated Drug Discovery with Grid
The Project:
SyntheticGestalt, an AI startup based in London and Tokyo, is developing an automatic system to make valuable drug discoveries en masse. Having received support from academic and governmental organizations in both the United Kingdom and Japan, they focus on the life sciences sector, developing machine learning models that make transformative discoveries such as novel drug candidate molecules and enzymes for the production of valuable molecules.
The SyntheticGestalt team learned about Grid after first experimenting with PyTorch Lightning.
The team runs machine learning algorithms and molecular simulations to validate potentially effective drug treatments. One of the most significant steps in their machine learning process is taking one-dimensional information about chemical molecules and proteins, which are just text strings, and converting them into information-rich vectors that represent their many properties. These vectors are then provided to the downstream models so that they have more information about the proteins and molecules, thus improving their predictions.
Because many of the machine learning models they develop aim to predict new chemical formulas, or to discover existing chemicals in datasets with hundreds of millions of data points, one of their biggest priorities is the ability to scale. SyntheticGestalt soon expects to predict hundreds of thousands to millions of these text strings, and would like to convert as many of them as possible into information-rich vectors.
In the simulation portion of SyntheticGestalt’s work, they convert molecule & protein information into 3D structures to test whether a target protein is likely to interact within a molecule in an effective way to target a specific disease. The simulation helps validate how well any given molecule and protein fit together. This simulation also requires a huge amount of sampling: it tests a wide variety of configurations and positions between molecule and protein to explore their binding interactions. There are many molecules to test against any given protein, and each of those molecules requires thousands of sampling steps.
The Challenge:
Finding a platform that allows them to scale easily has been critical to SyntheticGestalt’s success.
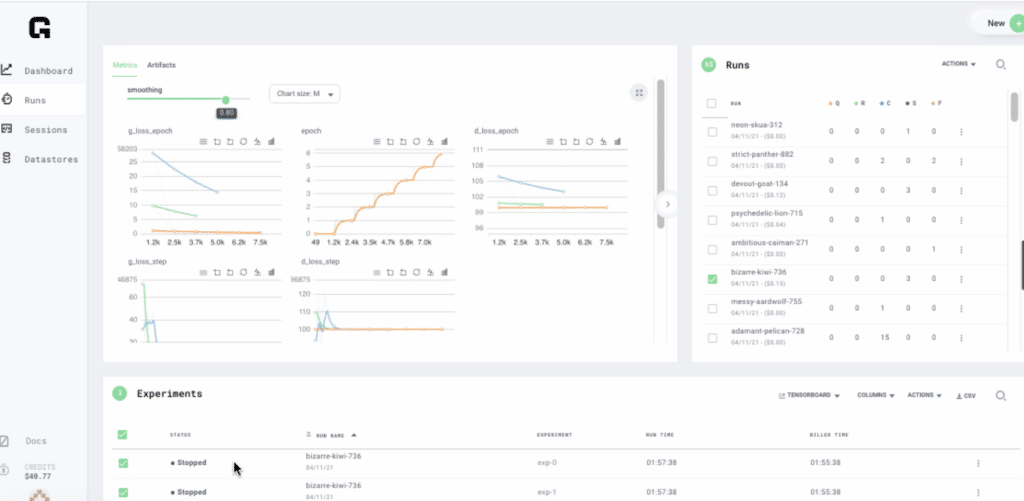
The team previously had difficulty running multiple jobs at the same time, and trying to scale caused time delays as they waited for the next job to become executable. Although they were able to hack together a workaround and run two experiments in parallel, this solution was not ideal and caused more complexity in their training strategy.
The Solution:
Grid instantly solved SyntheticGestalt’s main scaling issue. They were able to launch all their jobs at the same time, saving days, weeks and even over a month of work based on the workload they were running.
For example, they recently ran their largest set of confirmations to date of about 15,000 (the first step in their simulation process). If they had used their original pipeline, it would have taken nearly 40 days. With Grid, they were able to complete this job in a single day.
The SyntheticGestalt team doesn’t believe this would have been possible without Grid. Recent, cutting-edge research in the field of machine learning presents such scaling solutions as novel and far-reaching. What surprised the SyntheticGestalt team was that when they started working with Grid, they were able to quickly set up what they feel is equivalent to what is being theorized in this research.
With Grid, the team was able to simultaneously start all their experiments, setting them up as separate instances. They were then able to smoothly download and collect all the data back into their custom-built tree hierarchy structure.
“A 100 by 100 job we did (100 experiments with 100 different molecules) took only 4 hours in total. Prior to Grid we were running these experiments one at a time which would have taken 400 hours, which is just not feasible. Grid is a lot faster in every aspect.”
The team benefited from:
- Running jobs in parallel to increase efficiency and save a massive amount of time
- More efficiently managing AWS usage to accomplish more without increasing costs
- A UI that makes it easy to monitor usage in order to keep costs down
- Greater access to more hyperparameter values allowing them to more easily adjust their models and boosting confidence in the quality of their output
- Grid handling their infrastructure requirements
- Using Spot instances to auto-resume without losing any data
“We would be really struggling to do this work without a platform like Grid. We’d basically need to come up with our own solution which would take a long time. Especially since none of us are experts in this kind of computing infrastructure. Grid has been a massive savings in time.”
Getting Started with Grid:
Interested in learning more about how Grid can help you manage machine learning model development for your next project? Get started with Grid’s free community tier account (and get $25 in free credits!) by clicking here. Also, explore our documentation and join the Slack community to learn more about what the Grid platform can do for you.