
Supercharge your Cloud ML Workflow with Grid + Lightning
This post will highlight 7 ways Lightning and Grid can be used together to supercharge your ML workflow.
Grid enables scaling training from a laptop to the cloud without having to add a single line of MLOps code. The Grid platform supports all the classic Machine Learning Frameworks such as TensorFlow, Keras, PyTorch, and more. However leveraging Lightning supercharges Grid providing features such as Early Stopping, Integrated Logging, Automatic/Scheduled Checkpointing, and CLI. to make the traditional MLOps behind model training seem invisible.
Lighting is a lightweight wrapper for high-performance AI research that aims to abstract Deep Learning boilerplate while providing you full control and flexibility over your code. With Lightning, you scale your models not the boilerplate.
1. Lightning CLI + Grid Sweeps

As long as your training script can read script arguments. Grid allows running hyperparameter sweeps without changing a single line of code!
The LightningCLI provides a standardized mechanism to manage script arguments for Lightning Modules, DataModules, and Trainer objects out of the box.
Combined with the Grid Sweeps feature this means that with Lightning and Grid you can optimize almost any aspect of your model, training, and data pipeline from the numbers of Layers, Learning Rates, Optimization Functions, Transforms, Embedding Sizes, Data Splits and more, in parallel out of the box with no code changes.
Docs:
2. Lightning Early Stopping + Grid Runs
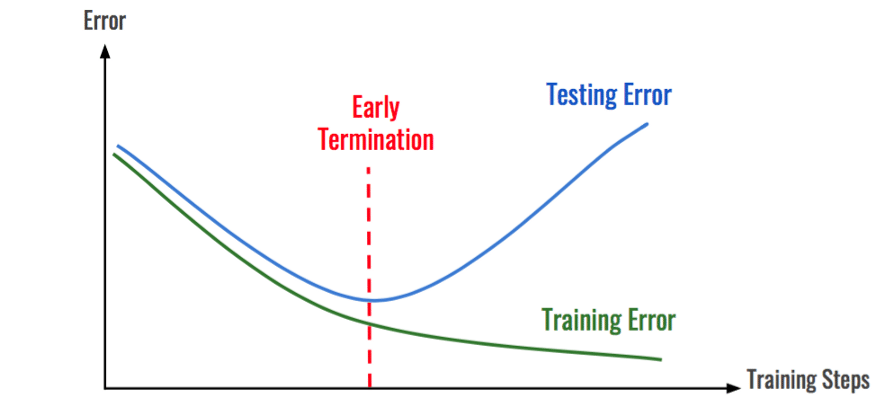
The EarlyStopping Callback in Lightning allows the Trainer to automatically stop when the given metric stops improving. You can define your own custom metrics or take advantage of our TorchMetrics package to select common metrics to log and monitor. Early Stopping is perfect for Grid Runs because it limits the time spent on experiments that lead to poor convergence or overfitting.
With Lightning EarlyStopping Thresholds into your PL Runs is a simple as adding the following few lines to your code. You can then pocket the savings or reinvest them into more promising configurations to take your model performance and convergence to the next level. For more information check out:
3. Lightning Max Time + Grid Cost Management

Have you ever wanted to estimate exactly how much a cloud training run will cost you? Well with PyTorch Lightning and Grid now you can. Lightning provides a trainer flag called max_time that can enable you to stop your Grid Run and save a checkpoint when you’ve reached the max allotted time. Combined with Grid’s ability to estimate how much a run will cost you per hour you can use this flag to better budget your experiments. This enables you to resume interruptible runs which can save up to 50-90% on training costs. If you are using PyTorch Lightning and a job gets interrupted you can reload it directly from the last checkpoint.
With this trick, you can better manage your training budget and invest it into more promising configurations to take your model performance and convergence to the next level. For more information check out:
4. Lightning Checkpointing + Grid Artifact Management
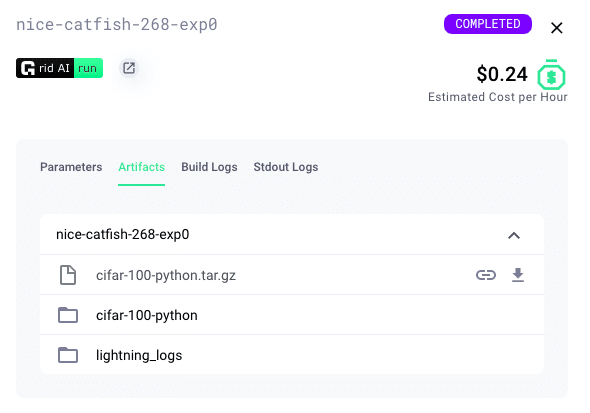
Checkpointing your training allows you to resume a training process in case it was interrupted, fine-tune a model or use a pre-trained model for inference without having to retrain the model. Lightning automatically saves a checkpoint for you in your current working directory, with the state of your last training epoch.
A Lightning checkpoint has everything needed to restore a training session including:
- 16-bit scaling factor (apex)
- Current epoch
- Global step
- Model state_dict
- Optimizers
- Learning Rate schedulers
- Callbacks
- The hyperparameters used for that model if passed in as hparams (Argparse.Namespace)
Anytime your Lightning script saves checkpoints, Grid captures those for you and manages them as artifacts. It does not matter which folder you save artifacts to… Grid will automatically detect those. Artifacts are accessible from both the Platform UI and the CLI and can be leveraged by lightning scripts to manually recover training if an Interruptible job gets pre-empted.
5. Lightning DataModules + Grid Optimized Datastores

A Lightning datamodule is a shareable, reusable class that encapsulates the 5 steps needed to process data for PyTorch.
- Download and Preprocess Raw Data .
- Clean and Optionally Cache Processed Data.
- Load Processed Data as
Dataset. - Create transforms for Data (rotate, tokenize, etc…).
- Wrap Data inside a Scalable
DataLoader.
Grid Datastores are optimized for these Machine Learning operations allowing your models to train at peak speed without taking on technical debt or needing to navigate the complexities of optimizing cloud storage for Machine Learning. They can be created through both the Grid command line and Web interfaces read more here.
6. Lightning Logging + TorchMetrics + Grid Visualization
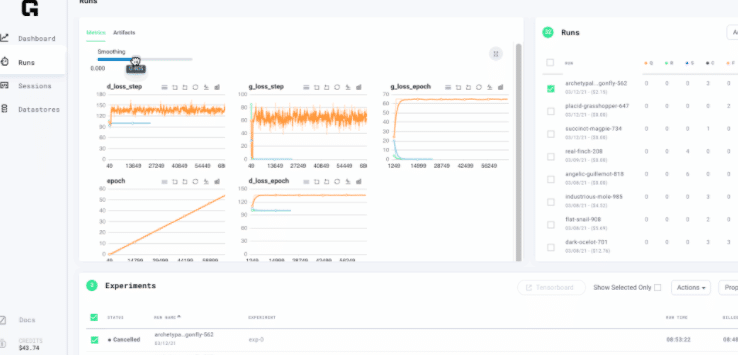
Lightning supports the most popular logging frameworks (TensorBoard, Comet, etc…). To use a logger, simply pass it into the Trainer. Lightning uses TensorBoard by default. TorchMetrics is a collection of Machine learning metrics for distributed, scalable PyTorch models and an easy-to-use API to create custom metrics.
You can use TorchMetrics in any PyTorch model, or with in PyTorch Lightning to enjoy additional features. This means your data is always placed on the same device as your metrics and with native logging support for metrics in Lightning.
Grid knows how to read directly from the lightning logger and provides mechanisms for both log tracking and metrics visualization out of the box.
7. One-Click Reproducible Runs
A core design philosophy of PyTorch Lightning is that all the components and code related to reproducibility should be self-contained. Such lightning modules contain all the default initialization parameters needed for reproducibility
Grid Runs make it simple to reproduce, share and embed run configurations as badges for GitHub and or Medium. Start a Run on Grid. Once completed, just go to the Run details, click on the Grid Run button and copy and paste that URL inside any Github repository markdown file so your friends run the same configuration.
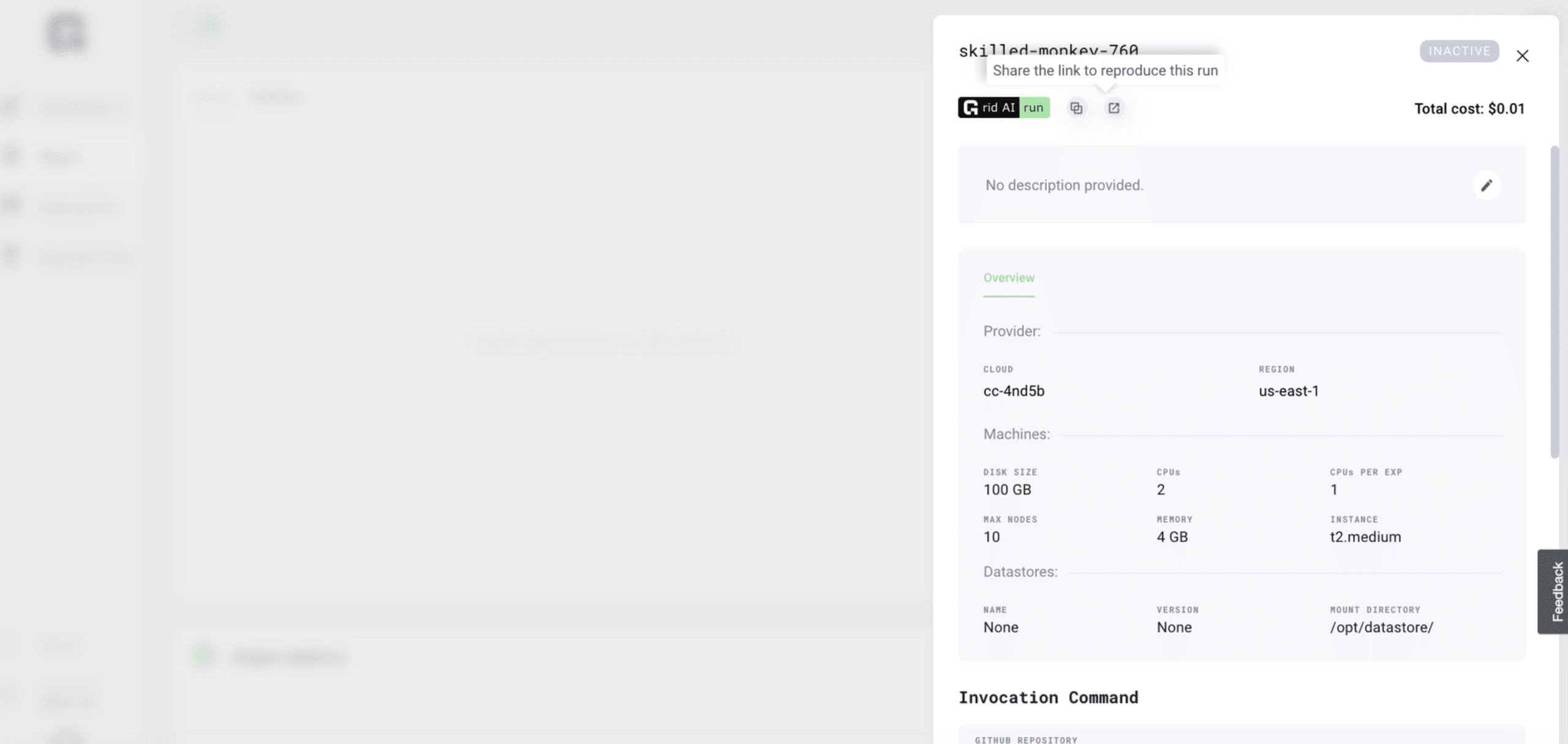
There you go! 7 ways Grid can supercharge your Lightning ML Workflow. Keep an eye out and join the grid community slack as every week we share new integrations and tricks for taking ML to the next level.
About the Author
Aaron (Ari) Bornstein is an AI researcher with a passion for history, engaging with new technologies and computational medicine. As Head of Developer Advocacy at Grid.ai, he collaborates with the Machine Learning Community, to solve real-world problems with game-changing technologies that are then documented, open-sourced, and shared with the rest of the world.