Author: Grid Team


Avoid Building and Maintaining an MLOps Training Environment
The Company:
AutoDevTech helps teams write better code by understanding code coverage, churn, and engagement. Using sophisticated machine learning techniques, the AutoDevTech platform accelerates a team’s efficiency by providing valuable insights into their development process in the context of industry norms, systematically exposing teams to best practices from some of the most well-crafted software.
Nick Gerner, AutoDevTech’s CEO/Founder and builder of many engineering teams, and Bora Banjanin, AutoDevTech’s lead Applied Scientist are tasked with the complex task of preserving the knowledge from the past and providing that knowledge to new engineers.
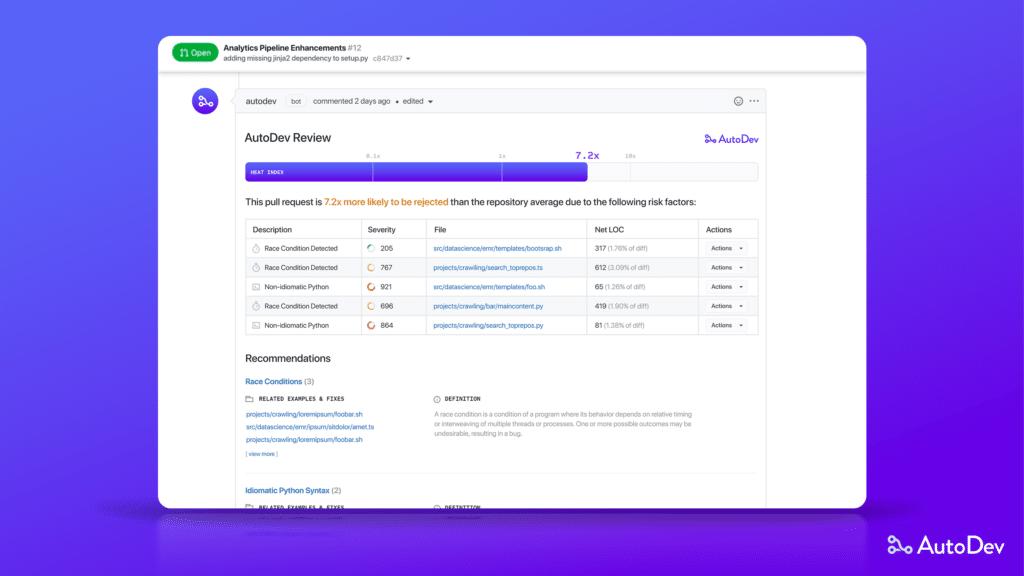
[AutoDevTech’s Review Assistant]
The Challenge:
AutoDevTech’s objective is to help write and validate code, making engineers more efficient. When it came time to scale their machine learning training, they quickly realized they themselves needed to be more efficient. They saw using Grid as an opportunity to avoid the complexity of building and maintaining their own MLOps training environment.
Prior to using Grid, the AutoDevTech team focused on traditional classic statistical regression models. They wanted to leverage more sophisticated models and evaluated infrastructure solutions such as Horovod and Sagemaker which they realized would require a greater engineering effort to achieve the desired state-of-the-art performance.
“Looking into a service like Grid, we wanted to be using more sophisticated methods and the only way to do that was with large scale distributed training.” – Bora Banjanin, Applied Scientist, AutoDevTech
The team benefited from:
- Training from laptop to cloud without code changes
- Easily scale to a large number of clustered machines
- Open-source software and the Open-source Community
- Avoiding a complex MLOps project
- Affordable and transparent pricing
Having enjoyed many of the benefits offered by the PyTorch Lightning platform and community, it was an easy decision for AutoDevTech to leverage Grid and have one team support all their ML lifecycle needs. PyTorch Lightning already provided a significant amount of simplification with Lightning Trainer, and given their plans to use DeepSpeed integration in the future, it was natural to work in the Grid platform.
“We can now turn out large experiments on large-scale distributed models, allowing my engineers to make decisions on what to do next. How big is the context, should it be big or smaller, etc. I don’t think we could get answers without using Grid.ai.” – Nick Gerner, CEO / Founder, AutoDevTech
The Solution:
The services Grid offered enabled their machine learning engineers to focus on machine learning. To compete and move to market faster, the team needed more sophisticated methods, and the only way to achieve their goals was through large-scale distributed training. The team continued to leverage their own AWS environment with Grid as a tenant in their Virtual Private Cloud (VPC). This allowed AutoDevTech to leverage its existing platform while also taking advantage of Grid.
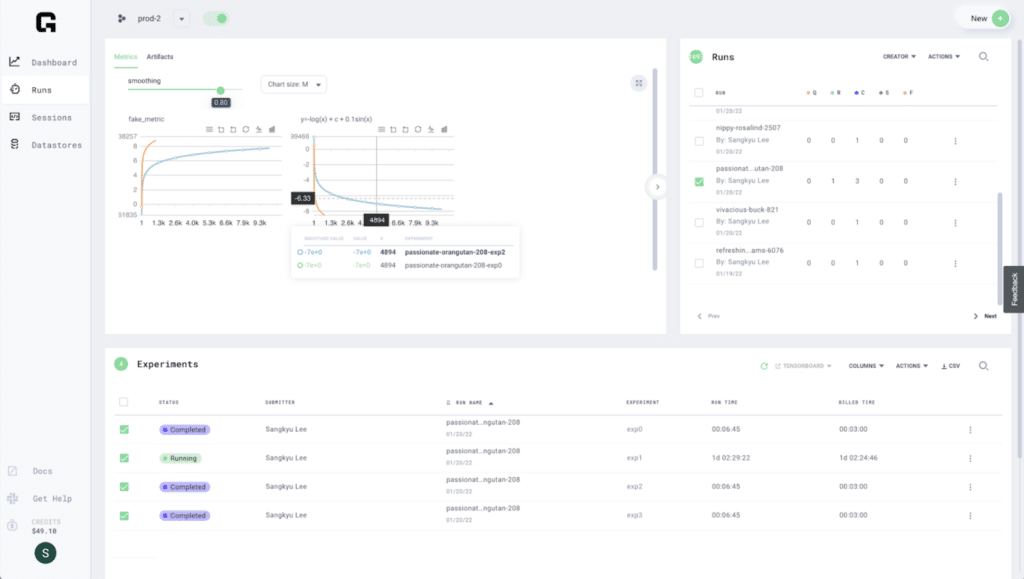
Grid Datastore management was an important function of the platform. Using the ability to pull data directly from the Grid. Datastore simplified data management and sped up development.
The simplicity of Grid Runs enabled teams to quickly determine which resources were available and easily leverage Spot instances to deliver maximum value. With Auto-resume, the AutoDevTech team will be able to restart instances when Spot instances are reclaimed.
Using a platform to keep up with the quickly changing machine learning space justified Nick’s decision to move to Grid. Additionally, the support from their staff, the PyTorch Lightning and Grid communities have made Grid a key component in maximizing the product they are serving their customers.
Getting Started with Grid:
Interested in learning more about how Grid can help you manage deep learning model development for your next project? Get started with Grid’s free community tier account (and get $25 in free credits!) by clicking here. Also, explore our documentation and join the Slack community to learn more about what the Grid platform can do for you.

How Neuroscientists Are Using AI To Understand Behavior
The Project
Dan Biderman is a Ph.D. candidate at Columbia University’s Center for Theoretical Neuroscience, advised by Statistics professors Liam Paninski and John Cunningham (both are also affiliated with the Grossman Center for the Statistics of Mind)
Dan is currently focusing on a project modeling animal behavior in videos, working to better understand how different brain regions (such as the cerebellum or the motor cortex) control natural movements. We connected with Dan to learn more about this project and how using Grid has enhanced their research.
The team began by tackling the well-known problem of pose estimation: how can we detect an animal’s joints from a raw video? With this information in hand, they hope to ask: What are the mechanical forces acting on each joint? What control strategies do biological agents use?
Pose estimation is a crowded area of computer vision. The research relies mostly on supervised learning: researchers collect a large amount of manually annotated images and train a neural network to predict joint positions from those images. Dan’s team is taking a new semi-supervised approach: they observed that raw unannotated videos already contain a rich spatiotemporal structure that is ignored by standard approaches. They are developing a video-centric software package called Lightning Pose, that combines PyTorch Lightning and Nvidia DALI to efficiently load video sequences to GPU and use them to train convolutional neural networks. As of now, they focus on videos collected by neuroscience labs that track whole-body movements, arm reaches, and eye movements. Dan used his various Grid sessions to develop and test new statistical tricks to allow the network to make sense of unannotated video frames. Dan and his team hope that in the coming months, their package can also be used on top of Grid. This way, researchers in the neuroscience community would be able to reproduce their results, contribute new ideas to their package, and perform scalable pose estimation neuroscience projects without worrying about infrastructure.
The Challenge
Before discovering Grid, the team managed all their cloud experiments themselves on AWS instances using boto3 scripts and vanilla PyTorch. They used S3 buckets to store large amounts of videos and images and ran into challenges setting up environments and managing SSH and Git. “90% of our time was invested in just making sure code runs,” said Dan.
The Solution
Dan learned of Grid.ai in the PyTorch Lightning Documentation and became curious about the workflow, and how Grid could help solve their pipeline management problem. Once Dan had implemented Grid, he was able to prototype new models for pose estimation. The team now has less code than existing algorithms due to a reduction in boilerplate using PyTorch Lightning, an integration with Nvidia DALI, and a solid State-Of-The-Art pose estimation package to help with future neuroscience projects.
As their Grid Sessions evolve, Dan is looking forward to having an increasingly pre-configured environment. He is currently enjoying the VS code integration, and also loves the Grid Community, as it provides powerful support in an accessible timeframe. When things go wrong, there are other humans to work with.
Grid exceeded Dan’s expectations through the Jupyter Lab Community of developers, SSH login logout, and the ability to see the status of the compute. The interaction with Instances from Grid CLI is also more pleasant to work with than AWS, and getting stats updates is clear and efficient.
“If someone’s use case is prototyping models, where there is a lot of uncertainty around model architecture, getting started with Grid will be much faster than doing it yourself on a cloud provider. In contrast to a university cluster, being able to explicitly control which hardware you are using is beneficial.” – Dan Biderman, Ph.D. Student
With Grid, longer-term plans will evolve as more users in the lab use Grid for their projects. The ability to share model results, simplify data loading, and have one platform to capture results will become more streamlined.
Getting Started with Grid
Interested in learning more about how Grid can help you manage deep learning model development for your next project? Get started with Grid’s free community tier account (and get $25 in free credits!) by clicking here. Also, explore our documentation and join the Slack community to learn more about what Grid can do for you.
Announcing the new Lightning Trainer Strategy API

Introducing LightningCLI V2

Announcing Lightning v1.5

Scale your PyTorch code with LightningLite
Lightning Tutorials in collaboration with the University of Amsterdam (UvA)

Train anything with Lightning custom Loops

Helping Consultants Apply Modern Methods To Industrial Problems
The Company
Willows.ai is a Montreal-based team that comprises machine learning, AI, and software experts who develop and deliver full-stack AI solutions for the manufacturing industry. Manufacturing has become a proving ground for leveraging the benefits of machine learning, where companies use technology to optimize visual systems to monitor and increase safety, track progress and provide real-time status updates, and reduce common process-driven waste. With expertise in computer vision and building robust, explainable machine learning solutions, Willows.ai helps manufacturers apply the latest research to their business problems.
The Problem
Prior to discovering Grid, the Willows.ai team managed a complex system to compare and analyze the results of their machine learning operations. This complexity often led to duplication of work and ballooning computational costs.
Willows knew that if they wanted to scale, they needed to avoid wasting precious time worrying about cloud infrastructure. They wanted a platform that freed up resource time and delivered results faster for both them and their clients.
Solution
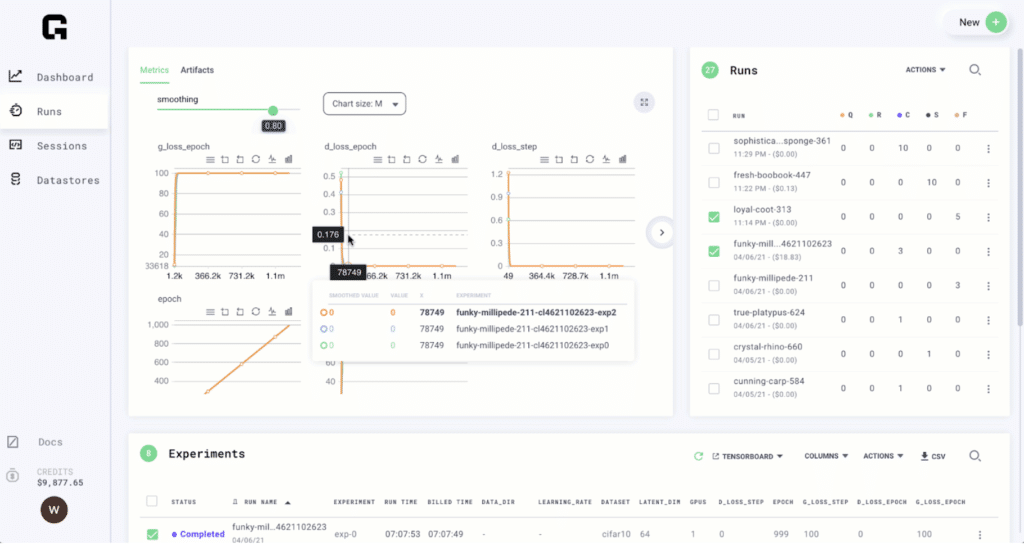
The Willows team discovered Grid.ai through the open source PyTorch Lightning community. The Grid platform, developed by the same team behind PyTorch Lightning, provided Willows with the capabilities they needed to manage scalable ML workflows. “We were able to solve our need to deliver more value by providing massive scale training to our clients,” explained Dr. Andrew Marble. It is extremely valuable for us to manage and see all the experiments that we create within a single dashboard view.” The Grid platform provides a unified view for managing run metrics, logs, and artifacts.
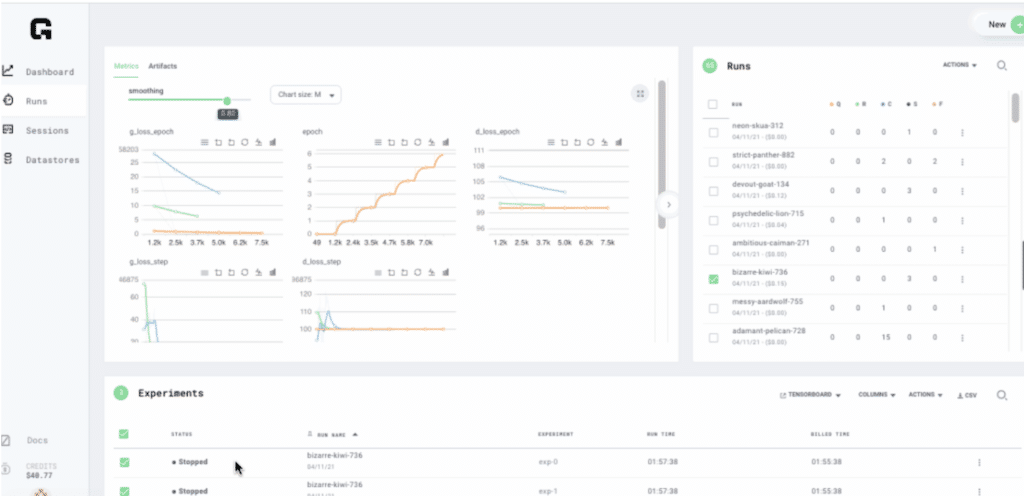
What Willows loved most about Grid is its Hyperparameter Optimization functionality that enabled them to scale variations of their models in parallel without needing to change their code or take on external dependencies.
“Being able to parameterize and add parameters to your model is where the real value [for Willows] is at. Grid’s Hyperparameter Sweeps are the most interesting feature to me”, Dr. Andrew Marble, Principal, Willows.ai.
Grid’s ability to manage interruptible compute such as spot instances through the click of a button reduced training costs for Willow.ai. Receiving real-time estimates before, during, and after, running experiments with Grid provided Willows with the transparency it needed to manage costs.

Getting Started With Grid.ai
Interested in learning more about how Grid can help you manage deep learning model development for your next project? Get started with Grid’s free community tier account (and get $25 in free credits!) by clicking here. Also, explore our documentation and join the Slack community to learn more about what the Grid platform can do for you.
Get to know more about Willows.ai, and connect with Dr. Andrew Marble via email at andrew@willows.ai