Author: Grid Team


Sharing Flash Demos with Grid Sessions, Gradio and Ngrok

5 Lightning Trainer Flags to take your PyTorch Project to the Next Level

Managing Machine Learning With Limited Resources
Machine Learning Made Easier With Grid.ai
In the race to implement machine learning, businesses of all sizes look for more accurate predictions that will allow them to stay ahead and differentiate themselves from the competition. One of the main roadblocks in getting there is the availability and affordability of machine learning resources. In this post, we speak with Felix Dittrich, the lead Machine Learning Developer at Memoresa to discuss how Grid.ai solved some of their ML challenges.
Discovering Grid
Based in Leipzig, Germany, Memoresa is an online platform and mobile app for easy estate planning, secure emergency provision, and digital organization with a system. Memoresa prides itself on helping estates organize their life documents to allow peace of mind for the organizing and planning of life.
Before finding Grid, Felix and his team felt challenged by all the steps related to training machine learning management, mainly due to their limited number of developers, capabilities, and resources brought on by a small team.
Memoresa captures image documents in their application; the ML engineer uses Grid to train their model to capture metadata for each user and auto-complete forms that are required to simplify the onboarding process. “We used Grid to train a custom named entity recognition model using Transformers and PyTorch Lightning as well as Onnx for quantization,” mentioned Felix.
While using the open-source PyTorch Lightning project to eliminate boilerplate in his code, Felix discovered Grid.ai. Founded by the creators of PyTorch Lightning, Grid is a platform designed to develop and train deep learning models at scale. The team at Memoresa needed an easy way to coordinate all the steps in training and managing machine learning models. Grid made it easy for Felix’s team to address this, as well as version control all their training data and model artifacts out of the box.
Exceeded Expectations!
Implementing Grid exceeded Felix and his team’s expectations. “All the steps related to end-to-end model training can be managed in one place. When my code runs in Sessions, I can scale it with Runs without any code changes.”
For start-ups like Memoresa, this means that it takes less time to go from an innovative prototype to a top-performing model. Felix remarked that he likes “how easily Grid Sessions enables me to prototype and debug my models and how I can scale my Session code with different hyperparameters configurations with Runs without any code modifications.”
“I love that Grid supports automatic versioning of datastores and model artifacts. Grid makes it simple to share datasets and model assets and code. As our company scales, it’s straightforward to introduce new teammates for collaboration.” This means that start-ups such as Memoresa can easily share the outcomes of their machine learning experiments reducing the time from expiration to business value.
Getting Started With Grid.ai
Interested in learning more about how Grid can help you manage deep learning model development for your next project? Get started with Grid’s free community tier account (and get $25 in free credits!) by clicking here. Also, explore our documentation and join the Slack community to learn more about what the Grid platform can do for you.

Best Practices to Rank on Kaggle Competition with PyTorch Lightning and Grid.ai Spot Instances
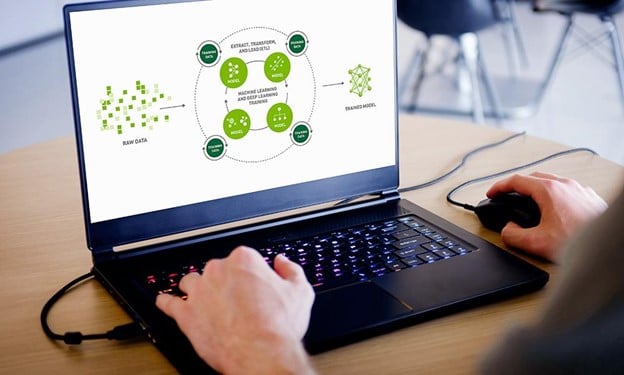
Simplifying Model Development and Building Models at Scale with PyTorch Lightning, Grid and NGC

Supercharge your Cloud ML Workflow with Grid + Lightning
This post will highlight 7 ways Lightning and Grid can be used together to supercharge your ML workflow.
Grid enables scaling training from a laptop to the cloud without having to add a single line of MLOps code. The Grid platform supports all the classic Machine Learning Frameworks such as TensorFlow, Keras, PyTorch, and more. However leveraging Lightning supercharges Grid providing features such as Early Stopping, Integrated Logging, Automatic/Scheduled Checkpointing, and CLI. to make the traditional MLOps behind model training seem invisible.
Lighting is a lightweight wrapper for high-performance AI research that aims to abstract Deep Learning boilerplate while providing you full control and flexibility over your code. With Lightning, you scale your models not the boilerplate.
1. Lightning CLI + Grid Sweeps

As long as your training script can read script arguments. Grid allows running hyperparameter sweeps without changing a single line of code!
The LightningCLI provides a standardized mechanism to manage script arguments for Lightning Modules, DataModules, and Trainer objects out of the box.
Combined with the Grid Sweeps feature this means that with Lightning and Grid you can optimize almost any aspect of your model, training, and data pipeline from the numbers of Layers, Learning Rates, Optimization Functions, Transforms, Embedding Sizes, Data Splits and more, in parallel out of the box with no code changes.
Docs:
2. Lightning Early Stopping + Grid Runs
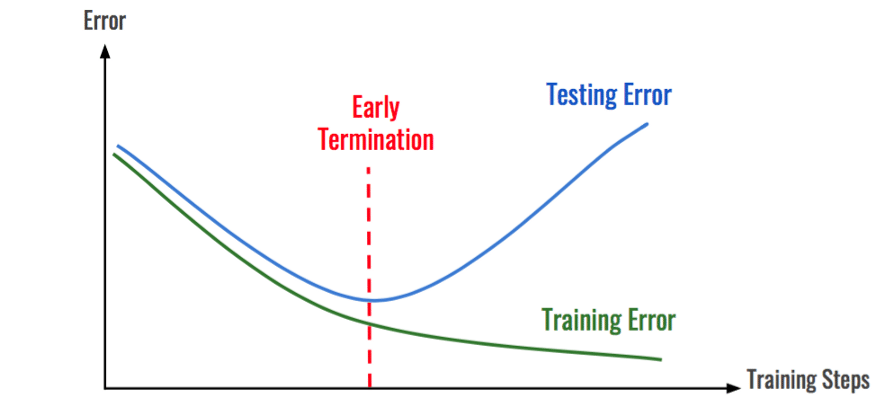
The EarlyStopping Callback in Lightning allows the Trainer to automatically stop when the given metric stops improving. You can define your own custom metrics or take advantage of our TorchMetrics package to select common metrics to log and monitor. Early Stopping is perfect for Grid Runs because it limits the time spent on experiments that lead to poor convergence or overfitting.
With Lightning EarlyStopping Thresholds into your PL Runs is a simple as adding the following few lines to your code. You can then pocket the savings or reinvest them into more promising configurations to take your model performance and convergence to the next level. For more information check out:
3. Lightning Max Time + Grid Cost Management

Have you ever wanted to estimate exactly how much a cloud training run will cost you? Well with PyTorch Lightning and Grid now you can. Lightning provides a trainer flag called max_time that can enable you to stop your Grid Run and save a checkpoint when you’ve reached the max allotted time. Combined with Grid’s ability to estimate how much a run will cost you per hour you can use this flag to better budget your experiments. This enables you to resume interruptible runs which can save up to 50-90% on training costs. If you are using PyTorch Lightning and a job gets interrupted you can reload it directly from the last checkpoint.
With this trick, you can better manage your training budget and invest it into more promising configurations to take your model performance and convergence to the next level. For more information check out:
4. Lightning Checkpointing + Grid Artifact Management
Checkpointing your training allows you to resume a training process in case it was interrupted, fine-tune a model or use a pre-trained model for inference without having to retrain the model. Lightning automatically saves a checkpoint for you in your current working directory, with the state of your last training epoch.
A Lightning checkpoint has everything needed to restore a training session including:
- 16-bit scaling factor (apex)
- Current epoch
- Global step
- Model state_dict
- Optimizers
- Learning Rate schedulers
- Callbacks
- The hyperparameters used for that model if passed in as hparams (Argparse.Namespace)
Anytime your Lightning script saves checkpoints, Grid captures those for you and manages them as artifacts. It does not matter which folder you save artifacts to… Grid will automatically detect those. Artifacts are accessible from both the Platform UI and the CLI and can be leveraged by lightning scripts to manually recover training if an Interruptible job gets pre-empted.
5. Lightning DataModules + Grid Optimized Datastores

A Lightning datamodule is a shareable, reusable class that encapsulates the 5 steps needed to process data for PyTorch.
- Download and Preprocess Raw Data .
- Clean and Optionally Cache Processed Data.
- Load Processed Data as
Dataset. - Create transforms for Data (rotate, tokenize, etc…).
- Wrap Data inside a Scalable
DataLoader.
Grid Datastores are optimized for these Machine Learning operations allowing your models to train at peak speed without taking on technical debt or needing to navigate the complexities of optimizing cloud storage for Machine Learning. They can be created through both the Grid command line and Web interfaces read more here.
6. Lightning Logging + TorchMetrics + Grid Visualization
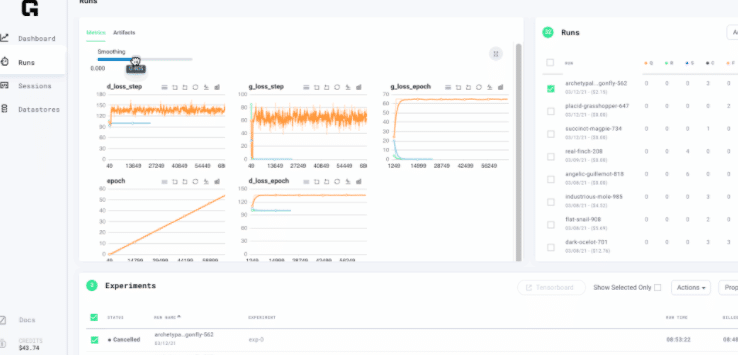
Lightning supports the most popular logging frameworks (TensorBoard, Comet, etc…). To use a logger, simply pass it into the Trainer. Lightning uses TensorBoard by default. TorchMetrics is a collection of Machine learning metrics for distributed, scalable PyTorch models and an easy-to-use API to create custom metrics.
You can use TorchMetrics in any PyTorch model, or with in PyTorch Lightning to enjoy additional features. This means your data is always placed on the same device as your metrics and with native logging support for metrics in Lightning.
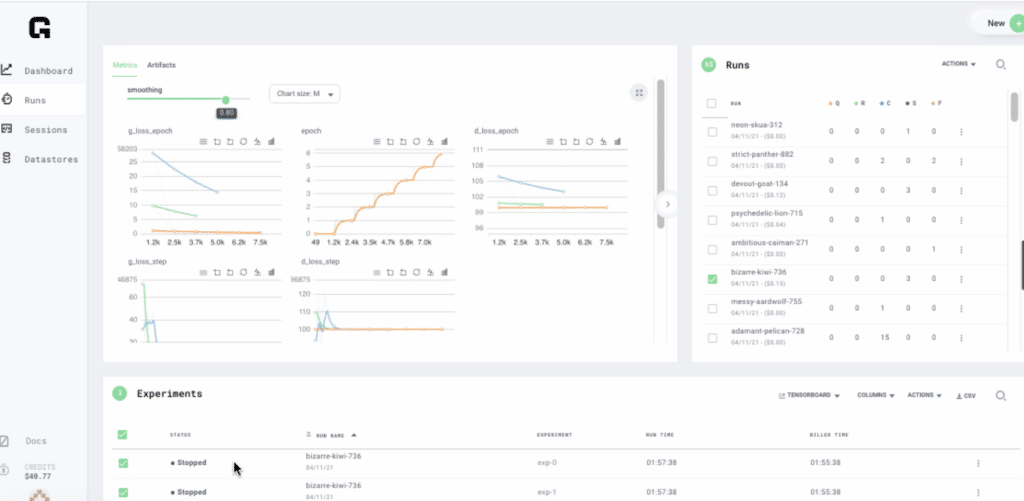
Grid knows how to read directly from the lightning logger and provides mechanisms for both log tracking and metrics visualization out of the box.
7. One-Click Reproducible Runs
A core design philosophy of PyTorch Lightning is that all the components and code related to reproducibility should be self-contained. Such lightning modules contain all the default initialization parameters needed for reproducibility
Grid Runs make it simple to reproduce, share and embed run configurations as badges for GitHub and or Medium. Start a Run on Grid. Once completed, just go to the Run details, click on the Grid Run button and copy and paste that URL inside any Github repository markdown file so your friends run the same configuration.
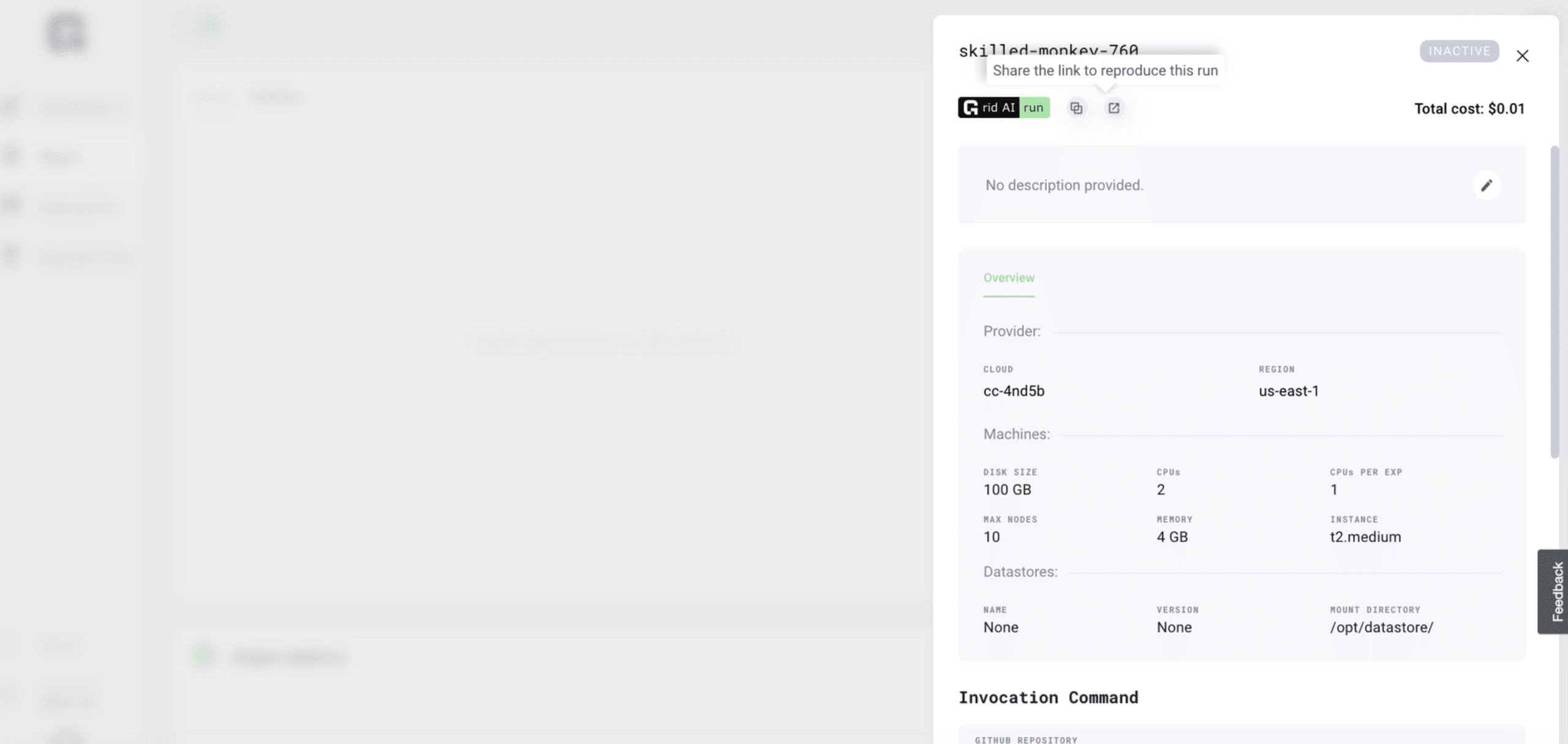
There you go! 7 ways Grid can supercharge your Lightning ML Workflow. Keep an eye out and join the grid community slack as every week we share new integrations and tricks for taking ML to the next level.
About the Author
Aaron (Ari) Bornstein is an AI researcher with a passion for history, engaging with new technologies and computational medicine. As Head of Developer Advocacy at Grid.ai, he collaborates with the Machine Learning Community, to solve real-world problems with game-changing technologies that are then documented, open-sourced, and shared with the rest of the world.
Scaling Production Machine Learning without the MLOps Overhead
Achieving state-of-the-art performance with modern machine learning requires far more compute than the average researcher or data scientists’ laptop can provide. Increasing model complexity requires a machine learning infrastructure that can scale. While traditional MLOps tooling enables scalability this comes at the cost of iteration speed.
This post walks through the shortcomings of modern MLOps solutions to this problem and explains how the Grid platform aims to decouple MLOps from Production ML.
What is MLOps?
Machine Learning Operations(MLOps) is the application of DevOps best practices to Machine Learning, enabling more efficient development, deployment, and life cycle management of machine learning applications.
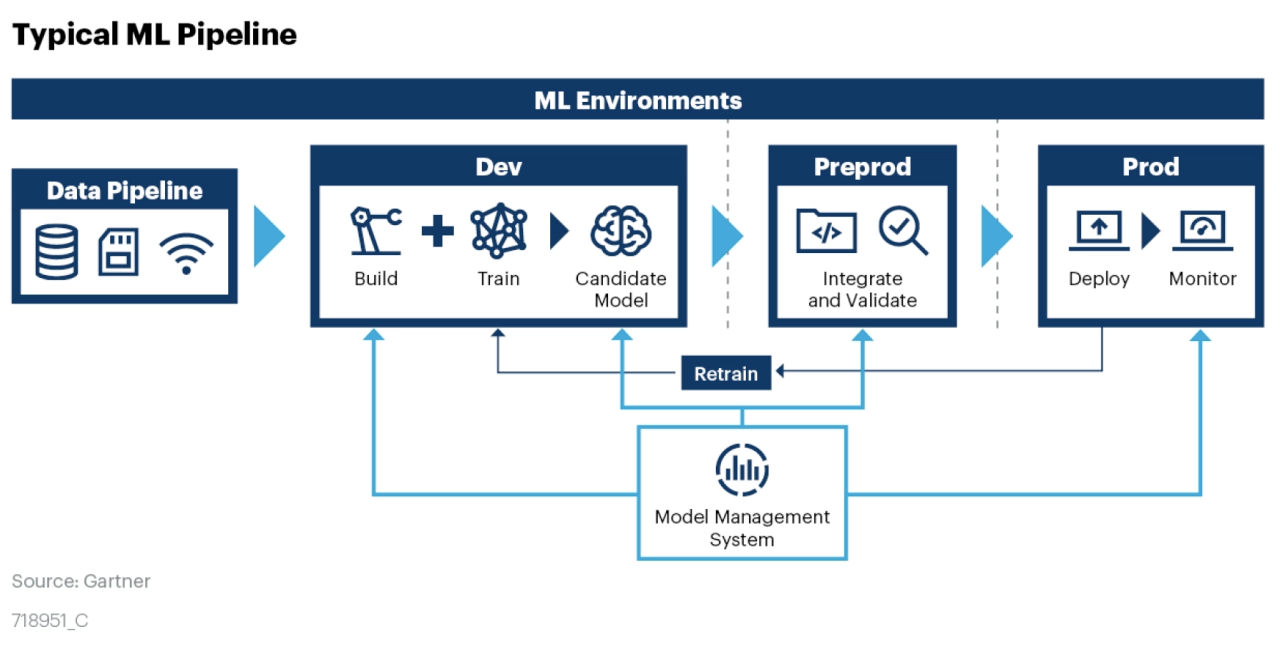
The above diagram from Gartner shows the typical Machine Learning Pipeline consisting of a Data Pipeline and Model management system. Models are the assets produced by Machine learning engineers and data scientists. These models must be continuously maintained and updated to keep up with ever-growing larger new datasets.
While MLOps pipelines enable machine learning to scale, managing your own MLOps pipeline raises a series of production challenges and costs that slows down model iteration and value.
The difference between differentiating in AI vs becoming obsolete is defined by model iteration speed. MLOps Pipelines need to be iterable and reproducible to scale to ever-changing patterns. For example, if a Machine Learning model was trained on a corpus from 2018 it might model a term such as, “corona” differently than a model that was continuously kept up to date.
If not properly managed, the model iteration process can often take days if not months, and require large teams of researchers, data scientists, machine learning engineers, software developers, and IT operations to iterate.
Data access and storage management for example is a critical bottleneck of the MLOps LifeCycle. Most existing MLOps tools require you to write pipelines that redownload data to disk before running.
Tracking machine learning dependencies and environment configurations can be time-consuming and overwhelming, often changing between iteration cycles.
Properly configuring network, storage, and hardware infrastructure for Machine Learning is hard, and improperly configured pipelines can lead to cascading iteration delays.
Further complicating matters, MLOps tooling and code is often tightly coupled with research code and deployment configurations contributing to vendor lock, less robust iteration cycles, and the current reproducibility crisis in machine learning.
Beyond MLOps with Grid
Developed by the creators of PyTorch Lightning, Grid is a machine learning platform that enables you to scale training from your laptop to the cloud without having to modify a single line of code.
Just as Lightning decoupled machine learning research from engineering code, Grid aims to decouple Machine Learning from MLOps. Whether you are an ML researcher or a data scientist, Grid is optimized to empower faster model iteration to turn your ideas into State of the Art.
Grid Datastores enable your training code to access vast volumes of data from the cloud as if it was located on your laptop’s local filesystem. Grid Datastores are optimized for Machine Learning operations allowing your models to train at peak speed without taking on technical debt or needing to navigate the complexities of optimizing cloud storage for Machine Learning. Grid Datastores can be created through both the Grid command line and Web interfaces read more here.
Grid Sessions run on the same hardware you need to scale while providing you with pre-configured environments to iterate the research phase of the machine learning process faster than before. Sessions are linked to Github, loaded with JupyterHub, and can be accessed through SSH and your IDE of choice without having to do any setup yourself. With sessions, you pay only for the compute you need (simply pause and resume) to get a baseline operational, and then you can scale your work to the cloud with runs.

Grid Runs enable you to scale your machine learning code to hundreds of GPUs and model configurations without needing to change a single line of machine learning code. If your code runs in a session with Grid Runs it will scale to the cloud. With support for major frameworks like Tensorflow, Keras, PyTorch, PyTorch Lightning Grid Runs enable all the Production MLOps Training best practices such as full hyperparameter sweep, multi node scaling, native logging, asset management, and interruptible pricing all out of the box you needing to modify a single line of machine learning code.

Conclusions
In this post, we learned about the tradeoff between iteration time and scalability with modern MLOps solutions and how Grid addresses these trade-offs by decoupling MLOps from Machine Learning.
We learned that:
- Grid DATASTOREs provide optimized, low-latency auto-versioned dataset management to speed up iteration time.
- Grid SESSIONs start preconfigured GitHub integrated interactive machines with the CPU/GPUs of your choice.
- Grid RUNs scale your code to the cloud enabling best practices such as hyperparameter sweeps, interruptible pricing, and optimized resource scheduling. This enables you to iterate ideas faster than before and take machine learning research and reproducibility to the next level.
Keep an eye out on this blog as we are constantly adding new features to streamline the model iteration & training process.
Register at grid.ai to get started and let us help you in your next Machine Learning project.
Contact us for Early Access to advanced Collaboration features.
Feel free to contribute to open source documentation https://github.com/gridai/grid-docs
Join us on the community slack!
Why we open sourced our documentation
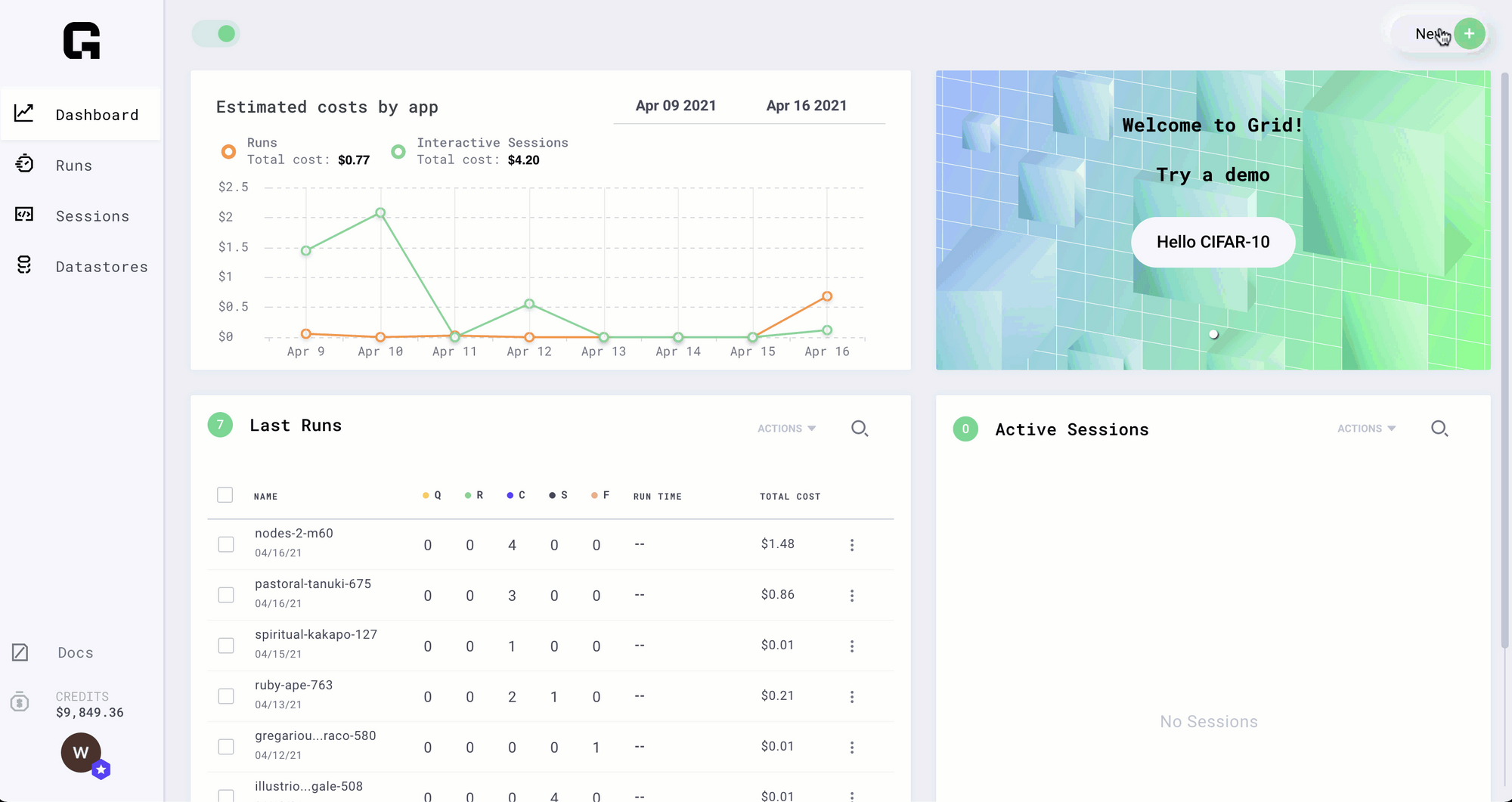
We launched Grid, a platform for developing and training machine learning models at scale, a few months ago and have received a great response from our already thriving Pytorch Lightning community. We are thankful for this support!
For an ML researcher or data scientist to be able to iterate on their ideas and algorithms fast, Grid gives them a platform where they don’t have to wait for infrastructure to be available or configured to scale easily.
As the Grid user base is growing, we are seeing feature requests specific to the workflows of researchers and data scientists and tricks people are finding useful when using the platform. Some community members expressed interest in adding their own examples to our documentation, and we thought that was a great idea! No one knows your code better than you, and why not empower you to add the example so others can benefit from it and you can share your work.
The platform is proprietary and accessible by registering on grid.ai, but we decided to open source the documentation to:
- Help users contribute their examples and tutorials
- Enable the community to benefit from rich documentation no matter what research or application they are working on
Our documentation is hosted on GitBook but has an integration with GitHub, so we decided to take advantage of that.
Register at grid.ai to get started
Contribute to https://github.com/gridai/grid-docs and see updated at https://docs.grid.ai/
Hyperparameter Sweeps for Machine Learning: Intro & Guide
From Retail, Mobility, and Finance to Personalized Medicine, advances in State-of-the-Art Deep Learning Research are transforming the world around us. Applications that once belonged in the realm of science fiction, from Driverless cars to Automated Retail stores, are now possible. Still, as anyone who has worked with machine learning knows, many obstacles need to be overcome when translating State-of-the-Art Research in these domains to production.
This post will demonstrate how you can leverage the Grid platform to find optimal Hyperparameters that help better translate research model performance to production.
What are Hyperparameters?
A Hyperparameter is any value in a Machine Learning System that can be changed. Common examples of Hyperparameter include values such as the Learning Rate and Number of Hidden Layers. Still, they can extend to more abstract concepts such as choosing a Model Backbone and Data Batch Size for your experiment.
It is a best practice to expose your machine hyperparameters as script arguments and tools like the Lightning CLI and Hydra make this easy.

Why does Choosing the Right Hyperparameters matter?
A small difference in a single hyperparameter can lead to a large performance gap. Therefore, a central component of Machine Learning research is to find the correct set of hyperparameters for a given task, such as ImageNet for Image Classification, Squad for Machine Reading Comprehension, or Coco for Object Detection.
Translating State-of-the-Art Research Models to production can be a rewarding yet often frustrating experience. Model performance heavily depends on hyperparameters, and since research hyperparameters are often chosen to match research datasets in production, we need to find new values to get the best results.
It can be challenging to find optimal hyperparameters for a production data distribution sequentially since the parameter search space is large and has very few optimal values.
What is a Hyper Parameter Sweep?
Hyperparameter sweeps, enabling finding the best possible combinations of hyperparameter values for ML models for a specific dataset through orchestrating a Run and managing experiments for configuration of our training code.
Grid + Hyperparameter Sweeps
Finding these values often requires managing complex on-premise or cloud architectures or performing significant code refactoring and MLOps vendor lock.
With Grid, you can perform Hyperparameter searches on training script parameters without needing to add a single line of code either from the UI or CLI inteface.
There are three commons ways to Sweep for Hyperparameters.
1. Grid Sweep – sweeps comprehensively over a range of hyperparameter options.
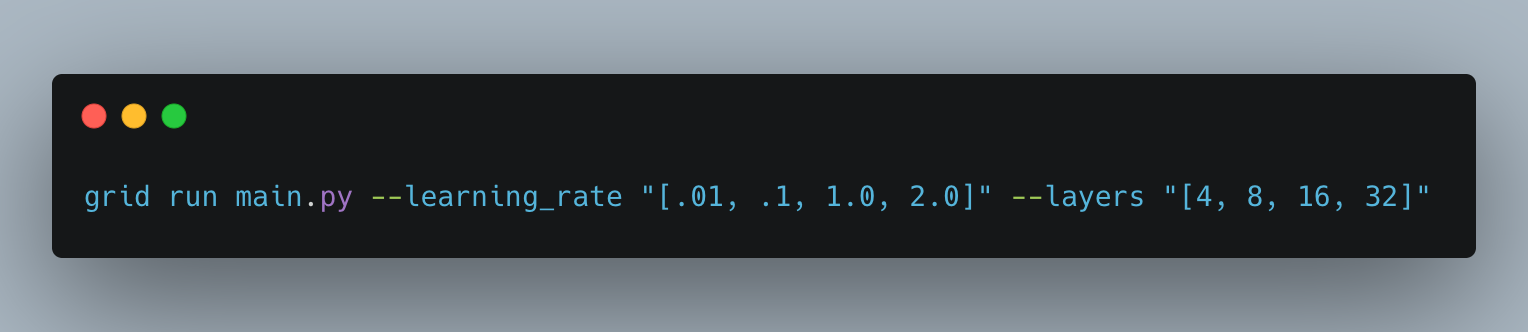
This would run 12 experiments for each of the parameter combinations provided above.
2. Random Sweep – sweep over a random subset of a range of hyperparameter options
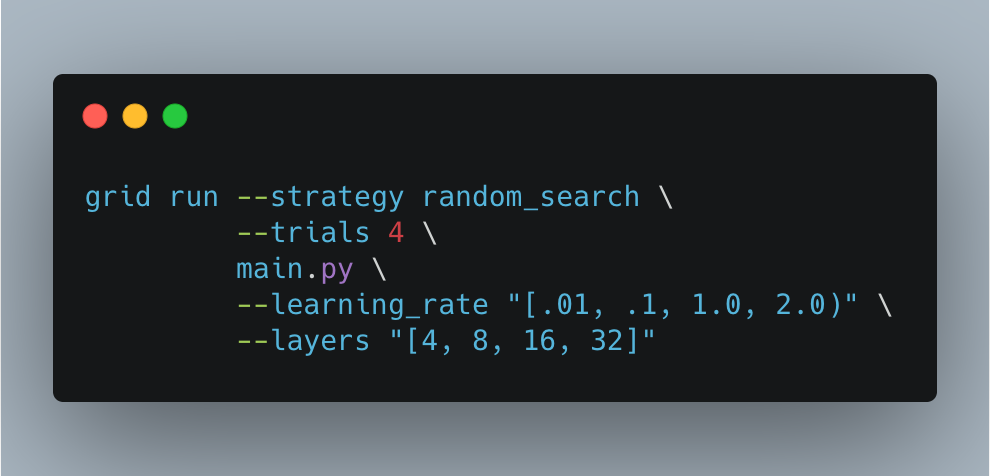
This would run 4 experiments.
3. Bayesian Optimization – There are alternative algorithms to random search that attempt to search the space more efficiently. In practice, random search is hard to beat with random search. In certain applications/models, bayesian can give you a slight advantage. However, these cases are rare.
Written by Ari Bornstein
Next Steps
- Get Started with Grid for Free Today
- Check out the Grid Sweep Docs
- To save on Search Costs, learn about Early Stopping with PL