Hyperparameter Sweeps for Machine Learning: Intro & Guide
From Retail, Mobility, and Finance to Personalized Medicine, advances in State-of-the-Art Deep Learning Research are transforming the world around us. Applications that once belonged in the realm of science fiction, from Driverless cars to Automated Retail stores, are now possible. Still, as anyone who has worked with machine learning knows, many obstacles need to be overcome when translating State-of-the-Art Research in these domains to production.
This post will demonstrate how you can leverage the Grid platform to find optimal Hyperparameters that help better translate research model performance to production.
What are Hyperparameters?
A Hyperparameter is any value in a Machine Learning System that can be changed. Common examples of Hyperparameter include values such as the Learning Rate and Number of Hidden Layers. Still, they can extend to more abstract concepts such as choosing a Model Backbone and Data Batch Size for your experiment.
It is a best practice to expose your machine hyperparameters as script arguments and tools like the Lightning CLI and Hydra make this easy.

Why does Choosing the Right Hyperparameters matter?
A small difference in a single hyperparameter can lead to a large performance gap. Therefore, a central component of Machine Learning research is to find the correct set of hyperparameters for a given task, such as ImageNet for Image Classification, Squad for Machine Reading Comprehension, or Coco for Object Detection.
Translating State-of-the-Art Research Models to production can be a rewarding yet often frustrating experience. Model performance heavily depends on hyperparameters, and since research hyperparameters are often chosen to match research datasets in production, we need to find new values to get the best results.
It can be challenging to find optimal hyperparameters for a production data distribution sequentially since the parameter search space is large and has very few optimal values.
What is a Hyper Parameter Sweep?
Hyperparameter sweeps, enabling finding the best possible combinations of hyperparameter values for ML models for a specific dataset through orchestrating a Run and managing experiments for configuration of our training code.
Grid + Hyperparameter Sweeps
Finding these values often requires managing complex on-premise or cloud architectures or performing significant code refactoring and MLOps vendor lock.
With Grid, you can perform Hyperparameter searches on training script parameters without needing to add a single line of code either from the UI or CLI inteface.
There are three commons ways to Sweep for Hyperparameters.
1. Grid Sweep – sweeps comprehensively over a range of hyperparameter options.
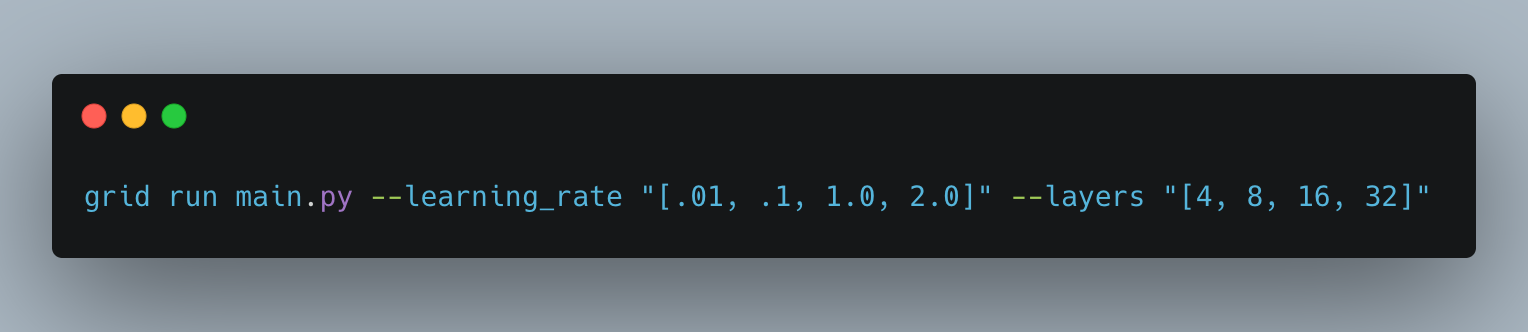
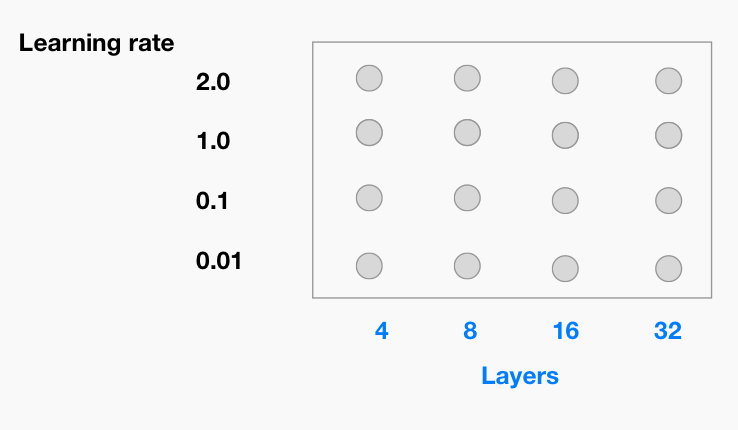
This would run 12 experiments for each of the parameter combinations provided above.
2. Random Sweep – sweep over a random subset of a range of hyperparameter options
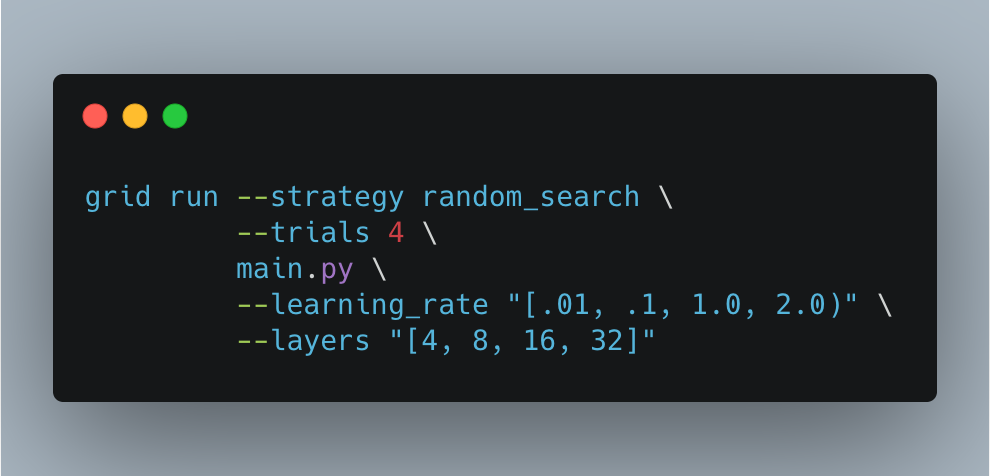
This would run 4 experiments.
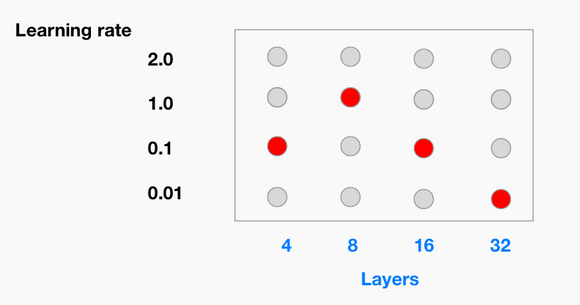
3. Bayesian Optimization – There are alternative algorithms to random search that attempt to search the space more efficiently. In practice, random search is hard to beat with random search. In certain applications/models, bayesian can give you a slight advantage. However, these cases are rare.
Written by Ari Bornstein
Next Steps
- Get Started with Grid for Free Today
- Check out the Grid Sweep Docs
- To save on Search Costs, learn about Early Stopping with PL