Scaling Production Machine Learning without the MLOps Overhead
Achieving state-of-the-art performance with modern machine learning requires far more compute than the average researcher or data scientists’ laptop can provide. Increasing model complexity requires a machine learning infrastructure that can scale. While traditional MLOps tooling enables scalability this comes at the cost of iteration speed.
This post walks through the shortcomings of modern MLOps solutions to this problem and explains how the Grid platform aims to decouple MLOps from Production ML.
What is MLOps?
Machine Learning Operations(MLOps) is the application of DevOps best practices to Machine Learning, enabling more efficient development, deployment, and life cycle management of machine learning applications.
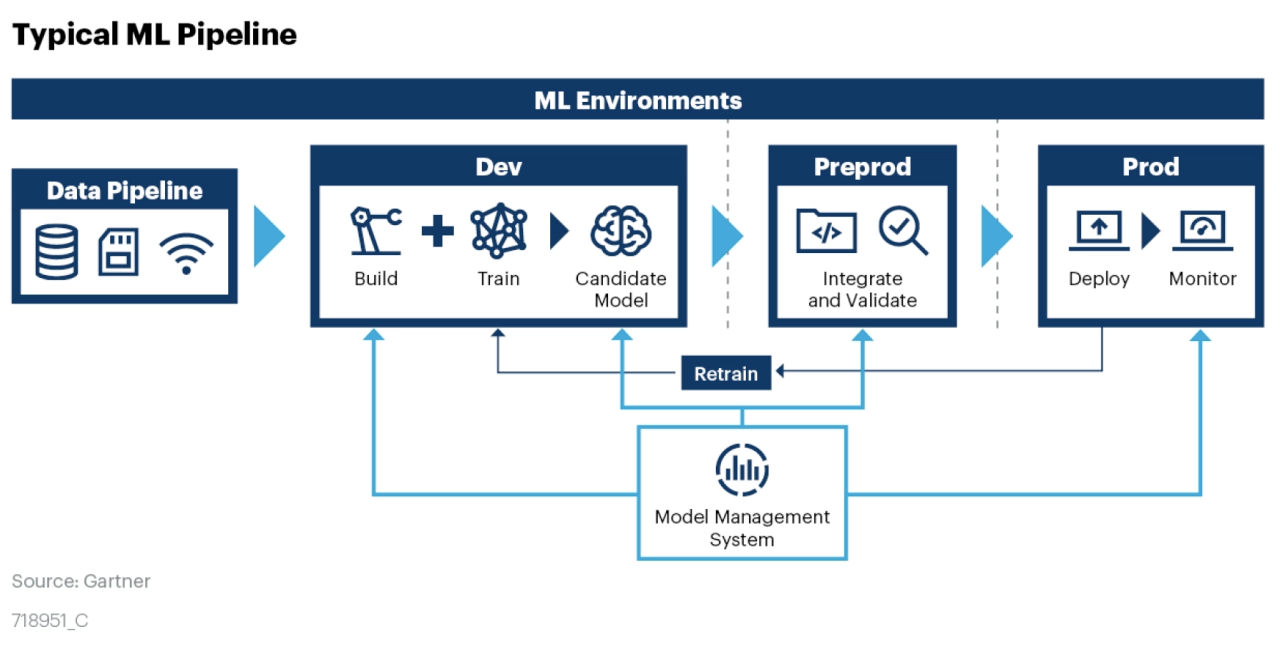
The above diagram from Gartner shows the typical Machine Learning Pipeline consisting of a Data Pipeline and Model management system. Models are the assets produced by Machine learning engineers and data scientists. These models must be continuously maintained and updated to keep up with ever-growing larger new datasets.
While MLOps pipelines enable machine learning to scale, managing your own MLOps pipeline raises a series of production challenges and costs that slows down model iteration and value.
The difference between differentiating in AI vs becoming obsolete is defined by model iteration speed. MLOps Pipelines need to be iterable and reproducible to scale to ever-changing patterns. For example, if a Machine Learning model was trained on a corpus from 2018 it might model a term such as, “corona” differently than a model that was continuously kept up to date.
If not properly managed, the model iteration process can often take days if not months, and require large teams of researchers, data scientists, machine learning engineers, software developers, and IT operations to iterate.
Data access and storage management for example is a critical bottleneck of the MLOps LifeCycle. Most existing MLOps tools require you to write pipelines that redownload data to disk before running.
Tracking machine learning dependencies and environment configurations can be time-consuming and overwhelming, often changing between iteration cycles.
Properly configuring network, storage, and hardware infrastructure for Machine Learning is hard, and improperly configured pipelines can lead to cascading iteration delays.
Further complicating matters, MLOps tooling and code is often tightly coupled with research code and deployment configurations contributing to vendor lock, less robust iteration cycles, and the current reproducibility crisis in machine learning.
Beyond MLOps with Grid
Developed by the creators of PyTorch Lightning, Grid is a machine learning platform that enables you to scale training from your laptop to the cloud without having to modify a single line of code.
Just as Lightning decoupled machine learning research from engineering code, Grid aims to decouple Machine Learning from MLOps. Whether you are an ML researcher or a data scientist, Grid is optimized to empower faster model iteration to turn your ideas into State of the Art.
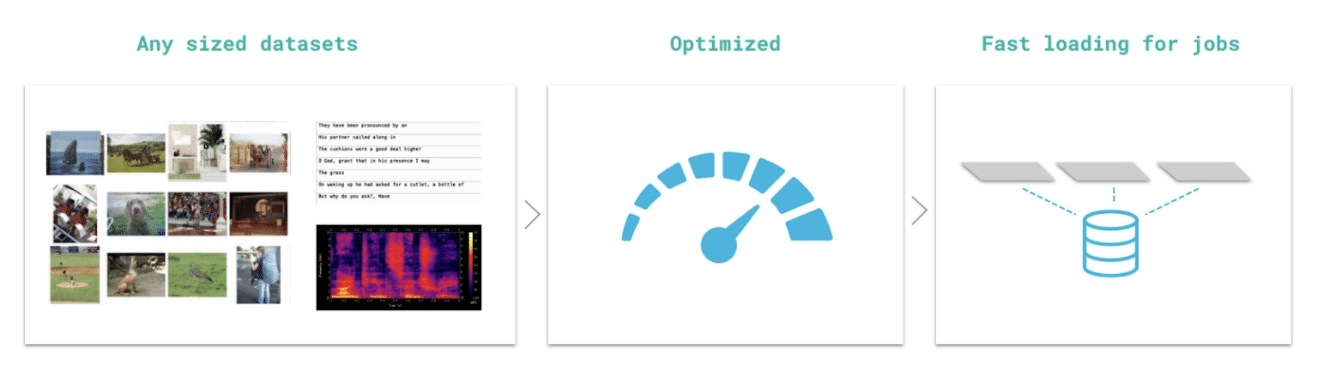
Grid Datastores enable your training code to access vast volumes of data from the cloud as if it was located on your laptop’s local filesystem. Grid Datastores are optimized for Machine Learning operations allowing your models to train at peak speed without taking on technical debt or needing to navigate the complexities of optimizing cloud storage for Machine Learning. Grid Datastores can be created through both the Grid command line and Web interfaces read more here.
Grid Sessions run on the same hardware you need to scale while providing you with pre-configured environments to iterate the research phase of the machine learning process faster than before. Sessions are linked to Github, loaded with JupyterHub, and can be accessed through SSH and your IDE of choice without having to do any setup yourself. With sessions, you pay only for the compute you need (simply pause and resume) to get a baseline operational, and then you can scale your work to the cloud with runs.

Grid Runs enable you to scale your machine learning code to hundreds of GPUs and model configurations without needing to change a single line of machine learning code. If your code runs in a session with Grid Runs it will scale to the cloud. With support for major frameworks like Tensorflow, Keras, PyTorch, PyTorch Lightning Grid Runs enable all the Production MLOps Training best practices such as full hyperparameter sweep, multi node scaling, native logging, asset management, and interruptible pricing all out of the box you needing to modify a single line of machine learning code.

Conclusions
In this post, we learned about the tradeoff between iteration time and scalability with modern MLOps solutions and how Grid addresses these trade-offs by decoupling MLOps from Machine Learning.
We learned that:
- Grid DATASTOREs provide optimized, low-latency auto-versioned dataset management to speed up iteration time.
- Grid SESSIONs start preconfigured GitHub integrated interactive machines with the CPU/GPUs of your choice.
- Grid RUNs scale your code to the cloud enabling best practices such as hyperparameter sweeps, interruptible pricing, and optimized resource scheduling. This enables you to iterate ideas faster than before and take machine learning research and reproducibility to the next level.
Keep an eye out on this blog as we are constantly adding new features to streamline the model iteration & training process.
Register at grid.ai to get started and let us help you in your next Machine Learning project.
Contact us for Early Access to advanced Collaboration features.
Feel free to contribute to open source documentation https://github.com/gridai/grid-docs
Join us on the community slack!